이상 징후를 절대 놓치지 마세요
완전한 어플리케이션 성능 관리를 위해서는 모든 요소를 관찰해야 합니다. 트레이스 및 조밀한 로그 데이터 분석을 통해 문제의 원인을 명확하게 특정할 수 있으며, 로그 옵저버 커넥트를 통해 모든 요소에 대한 상관 관계 분석을 진행하고 더 빠른 문제 해결이 가능합니다.
옵저버빌러티
엔드 투 엔드 가시성을 확보하면 더 빨리 문제를 찾아낼 수 있습니다.
AI 기반 장애 해결을 사용하면, 시스템 성능 저하와 그 근본 원인을 자동적으로 연계할 수 있으며, 평균 수리 시간(MTTR)을 단축할 수 있습니다. 이를 통해 모든 문제를 더 손쉽게 식별하고, 개입 범위를 한정하여, 효과적 해결이 가능합니다.
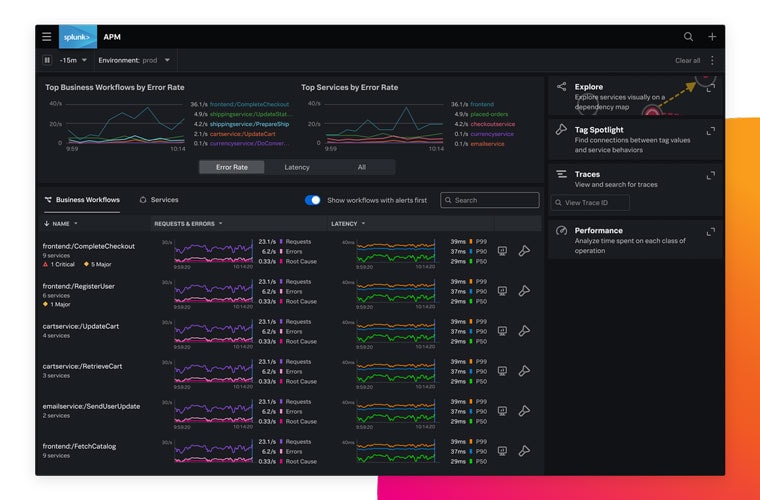
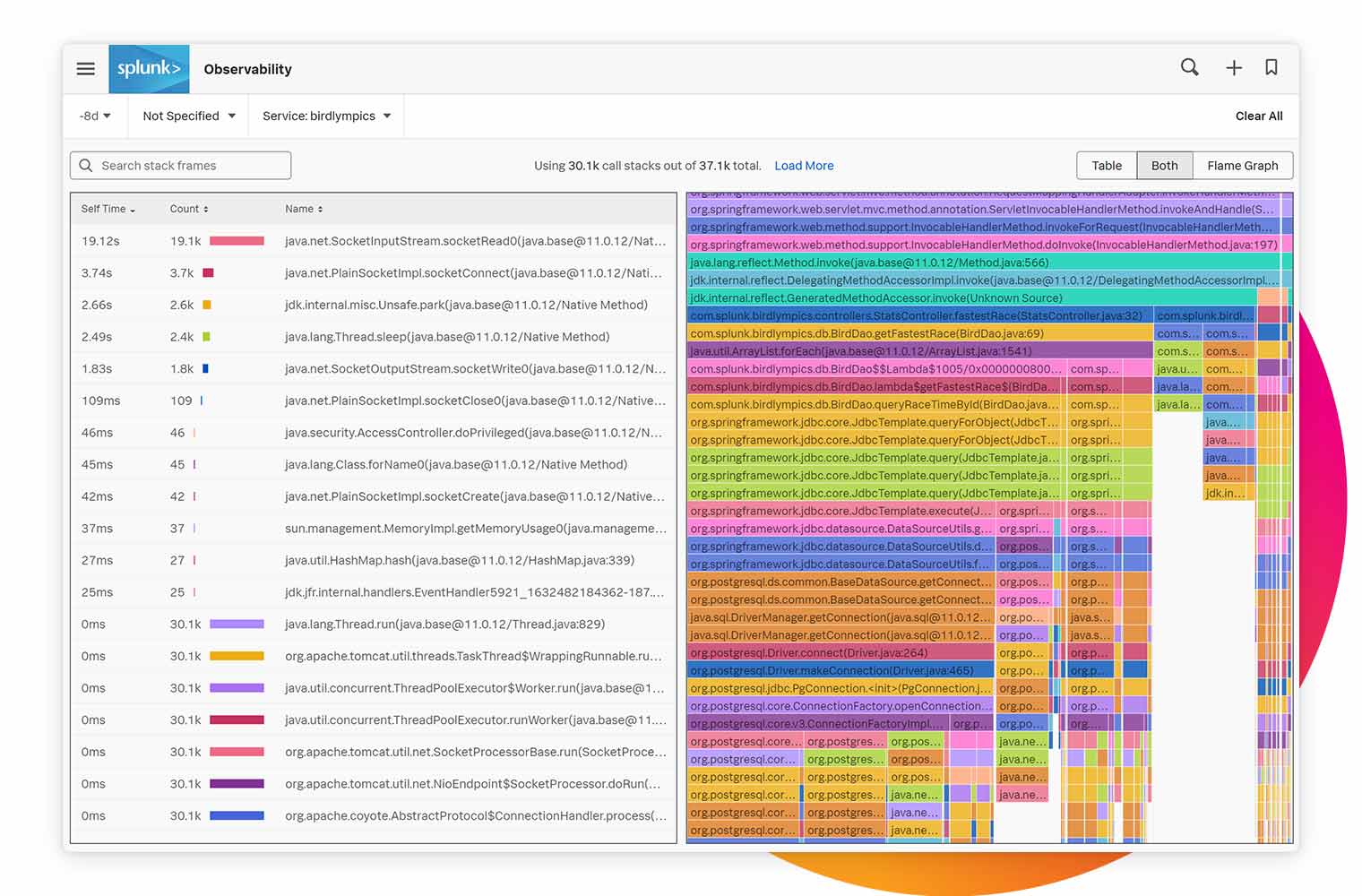
Splunk APM은 샘플링된 일부 정보만 취합하는 것이 아니라 모든 트레이스 정보를 수집하기 때문에, 모든 이상 징후를 탐지하고 모든 릴리스 내역에 대해 즉각적 피드백 제공이 가능합니다.
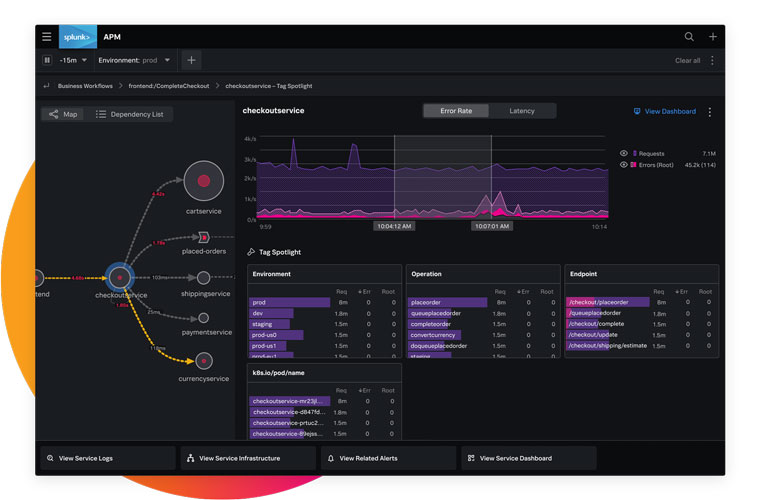
Splunk APM에서 동적으로 생성하는 서비스 맵을 사용하면, DevOps 팀은 모든 서비스 상호 작용, 추론된 서비스, 처리 종속성 및 성능에 대해 즉각적 가시성을 확보할 수 있습니다.
시간 지연 또는 오류 이벤트를 태그 값과 빠르게 연계시켜, 전체 시스템에서 트레이스가 작동하는 방식을 단일 중앙 지점에서 손쉽게 이해할 수 있습니다.
공통 서비스 또는 태그를 기반으로 종단 간 트레이스를 그룹화하여 Splunk APM에서 중요한 비즈니스 트랜잭션을 추적할 수 있습니다. 개발자는 마이크로서비스가 연관성이 있는 모든 워크플로에 어떤 영향을 미치는지 시각화할 수 있습니다.
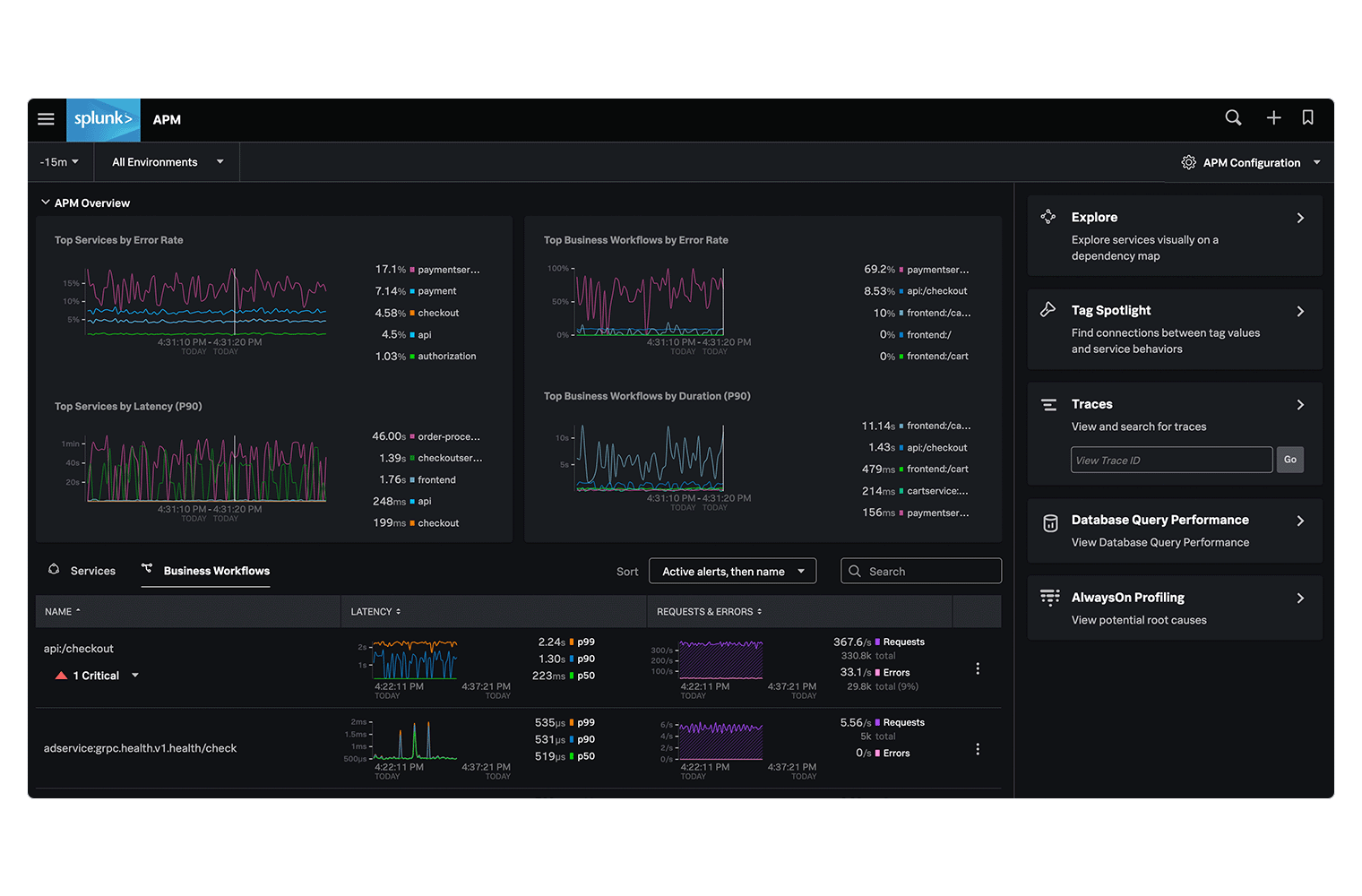
동적 경보를 사용하면 DevOps 팀은 경보를 정적 임계값, 갑작스러운 변경 또는 과거의 이상 징후를 기반으로 생성하도록 설정이 가능하며, 경보를 보다 손쉽게 받고 경보의 수를 줄일 수 있습니다.
Splunk APM의 "Always On" 코드 프로파일링은 트레이스 데이터 컨텍스트에서 코드 레벨의 퍼포먼스를 분석하여, 병목 현상을 해결하고 클라우드 네이티브 및 모놀리틱 어플리케이션의 성능을 최적화하는 데 도움을 줍니다.

Splunk는 모든 로그, 메트릭 및 트레이스를 수집하여 우리 플랫폼 내에서 일어나는 모든 이벤트를 이해할 수 있도록 도와줍니다. 그 결과 우리는 질문을 던지고 그에 대한 답을 얻을 수 있습니다.
Splunk APM is the most advanced application for performance monitoring and troubleshooting for cloud-native applications and microservices.
Splunk Observability Cloud is very easy to monitor and use and helps in resolving any issues that we can come across in our organization.
I use it on a daily basis to monitor project performance, particularly for foreign clients in the EU, because it informs me of latency between containers and databases, allowing me to pinpoint the source of the problem.